RefineLoc: Iterative Refinement for Weakly-Supervised Action Localization
Abstract
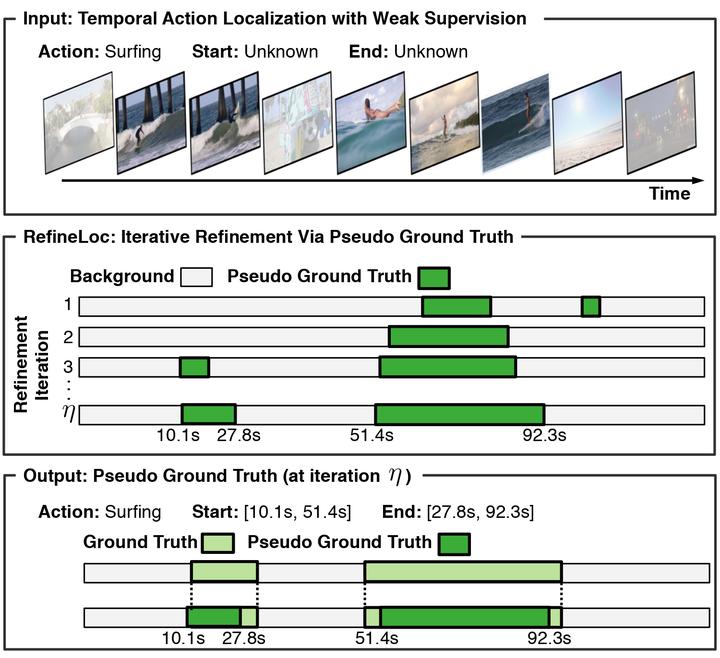
Video action detectors are usually trained using datasets with fully-supervised temporal annotations. Building such datasets is an expensive task. To alleviate this problem, recent methods have tried to leverage weak labeling, where videos are untrimmed and only a video-level label is available. In this paper, we propose RefineLoc, a novel weakly-supervised temporal action localization method. RefineLoc uses an iterative refinement approach by estimating and training on snippet-level pseudo ground truth at every iteration. We show the benefit of this iterative approach and present an extensive analysis of five different pseudo ground truth generators. We show the effectiveness of our model on two standard action datasets, ActivityNet v1.2 and THUMOS14. RefineLoc shows competitive results with the state-of-the-art in weakly-supervised temporal localization. Additionally, our iterative refinement process significantly improves the performance of two state-of-the-art methods, setting a new state-of-the-art on THUMOS14.
Alejandro Pardo
PhD Student in Computer Vision
My research interest is with video processing and analysis, and its applications.