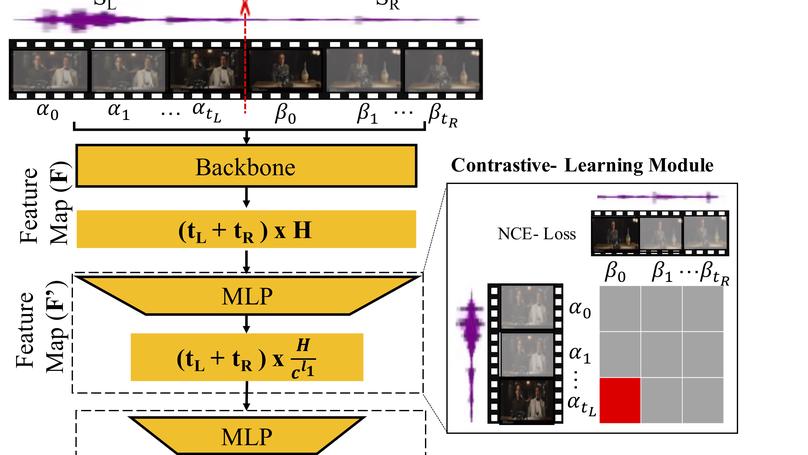
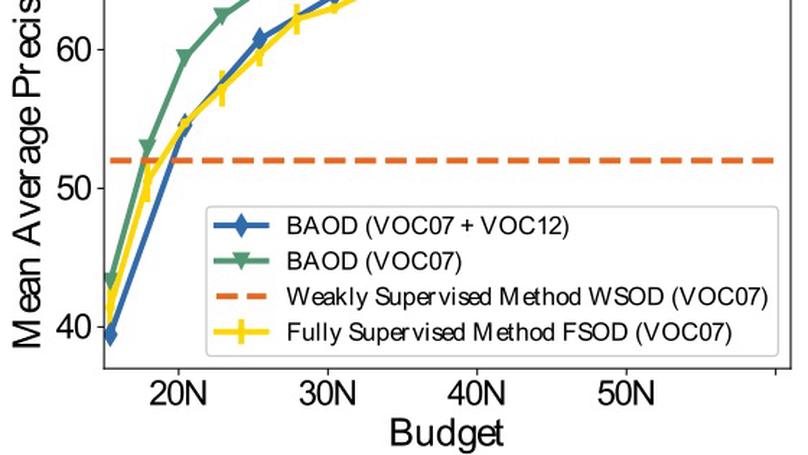
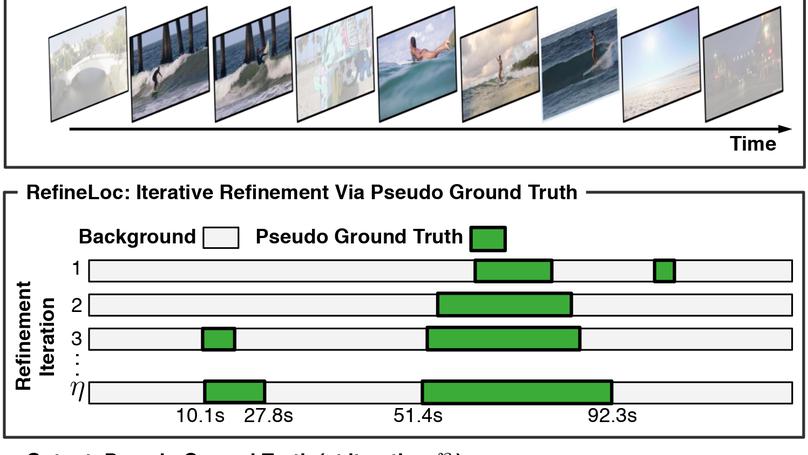
Recent works have begun to discover significant limitations in video-language grounding, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions). MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD enables a novel and more challenging version of video-language grounding, where short temporal moments must be accurately grounded in diverse long-form videos.